Learning with Function Approximator
1. Action-value function appoximation
앞에서는 value funciton을 사용했지만 model free가 되려면 action value function을 사용해야 합니다. 그러한 알고리즘을 그림으로 표현하자면 아래와 같습니다. policy evaluation은 parameter의 update로 진행하며 policy improvement는 그렇게 update된 action value function에 $$\epsilon-greedy$$한 action을 취함으로서 improve가 됩니다.
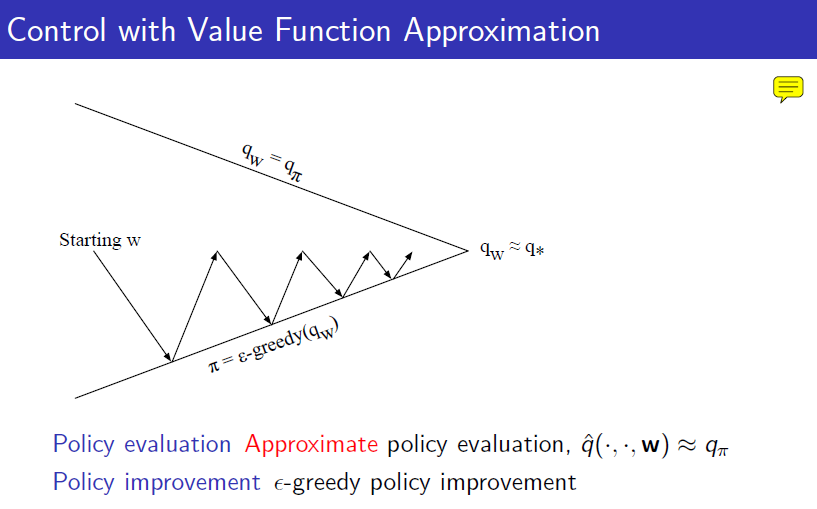
앞에서 value function으로 했던 내용을 반복하면 아래와 같습니다.

True value function을 대체하는 것도 아래와 같습니다.

2. Example
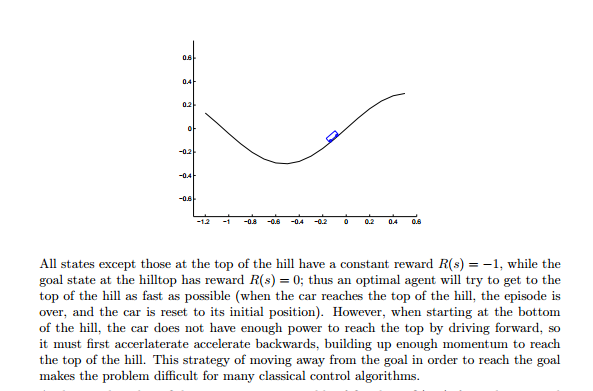
Appximation을 통한 강화학습의 예로 cartpole, acrobot과 같이 classical control로 유명한 Mountain Car를 사용 하였습니다. 이 예제의 목표는 Goal에 올라가는 것입니다.
https://see.stanford.edu/materials/aimlcs229/problemset4.pdf
문제의 정의는 다음과 같습니다. 정상을 제외한 모든 곳은 time step마다 reward를 -1씩 받게 됩니다. 따라서 최대한 빠른 시간 내에 goal에 올라가는 것을 agent는 목표로 하게 됩니다. 또한 바로 uphill을 할 추력은 차에게 없다고 가정을 한다면 차가 왔다 갔다하면서 중력으로 가속시켜서 올라가야하기 때문에 문제는 어려워집니다. 이러한 문제는 강화학습은 가볍게 풀어줍니다.
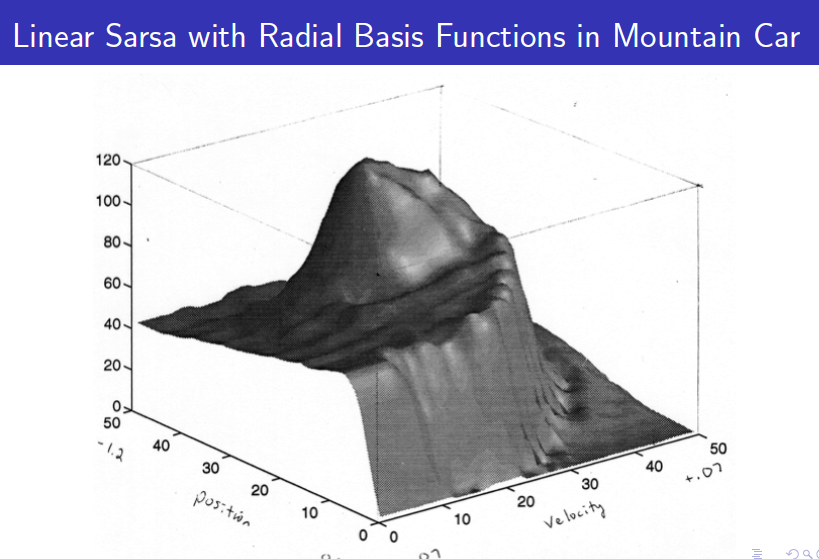
많은 control문제에서 그러듯이 state는 위치와 속도로 정의됩니다. 두 개의 component를 가지기 때문에 state-space는 2차원이 됩니다. 강화학습을 통해 optima policy를 알아내려면 각 state의 value function을 알아야하는데 state가 continuouns하기 때문에 기존의 table방법으로는 풀 수가 없는 문제입니다. 따라서 value function approximator를 통해서 모든 state의 value function을 함수화해서 표현할 수 있고 sampling을 통해서 experience를 통해서 value function을 학습해나갑니다. 아래는 그 과정을 보여주는 그래프입니다.

학습이 완료된 value function은 아래와 같이 표현할 수 있고 agent가 하는 일은 각 state에서 가장 높은 value function을 가진 state로 계속 이동하는 것입니다.
3. Batch Methods
지금까지 SGD(Stochastic Gradient Descent)을 통해서 parameter를 update하는 방법을 사용했었습니다. 하지만 이 방법은 아래와 같은 문제가 있습니다.
 SGD처럼 차근차근 gradient를 따라서 parameter를 udpate하는 것이 아니고 training data(agent가 경험한 것)들을 모아서 한꺼번에 update하는 것이 "Batch Methods"입니다. 하지만 Batch방법은 한 번에 업데이트하는 만큼 그 많은 데이터들에 가장 잘 맞는 value function을 찾기가 어렵기 때문에 SGD와 Batch방법의 중간을 사용하는 경우도 많습니다. 예를 들면, step-by-step으로 업데이트하는 것이 아니고 100개의 데이터가 모일 때까지 기다렸다가 100번에 한 번씩 업데이트하는 "mini-batch"방법도 있습니다.
SGD처럼 차근차근 gradient를 따라서 parameter를 udpate하는 것이 아니고 training data(agent가 경험한 것)들을 모아서 한꺼번에 update하는 것이 "Batch Methods"입니다. 하지만 Batch방법은 한 번에 업데이트하는 만큼 그 많은 데이터들에 가장 잘 맞는 value function을 찾기가 어렵기 때문에 SGD와 Batch방법의 중간을 사용하는 경우도 많습니다. 예를 들면, step-by-step으로 업데이트하는 것이 아니고 100개의 데이터가 모일 때까지 기다렸다가 100번에 한 번씩 업데이트하는 "mini-batch"방법도 있습니다.
위에서 말하는 SGD의 문제점인 experience data를 한 번만 사용하는 것이 비효율적이다라고 말하는 점에 대해서는 한 번만 사용하지 않고 여러번 사용하는 것으로 문제를 해결할 수 있습니다. 하지만 어떤 방법으로 여러번 experience data를 활용할 것인가에 대해서 experience replay가 그 답을 말해줍니다.
4. Experience Replay
Experience Replay는 아래와 같습니다. 뒤에서 설명하겠지만 Deepmind에서 Atari Game에 사용했던 알고리즘이고 아래와 같습니다. replay memory라는 것을 만들어 놓고서 agent가 경험했던 것들을 $$(st, a_t,r{t+1},s_{t+1})$$로 time-step마다 끊어서 저장해놓습니다. action-value function의 parameter를 update하는 것은 time-step마다 하지만 하나의 transition에 대해서만 하는 것이 아니고 모아놓았던 transition을 repaly memory에서 100개면 100개 200개면 200개씩 꺼내서 그 mini-batch에 대해서 update를 진행합니다.

이렇게 할 경우에 sample efficient할 수도 있지만 또한 episode내에서 스텝 바이 스텝으로 업데이트를 하면 그 데이터들 사이의 correlation 때문에 학습이 잘 안되는 문제도 해결할 수 있습니다.