Bellman Optimality Equation
앞에서 현재 state의 value function과 next state의 value function 사이의 관계식인 Bellman equation에 대해서 살펴보았습니다. 하지만 왼쪽 목차를 보면 Bellman equation이 Bellman expectation equation과 Bellman optimality equation으로 구분됩니다.
Bellman expectation equation
다시 이전의 Bellman expectation equation을 살펴보겠습니다.

위 두 식은 expectation의 형태로 표현된 Bellman equation입니다. 따라서 이 식을 Bellman expectation equation이라고 부릅니다. 보통은 따로 expectation이라는 단어를 쓰지 않고 Bellman equation이라고 합니다. 위 식은 하지만 수학에서의 등호라기보다는 코딩에서 쓰이는 대입의 의미의 등호에 가깝습니다. 여기서 Backup의 개념이 나오게 됩니다.
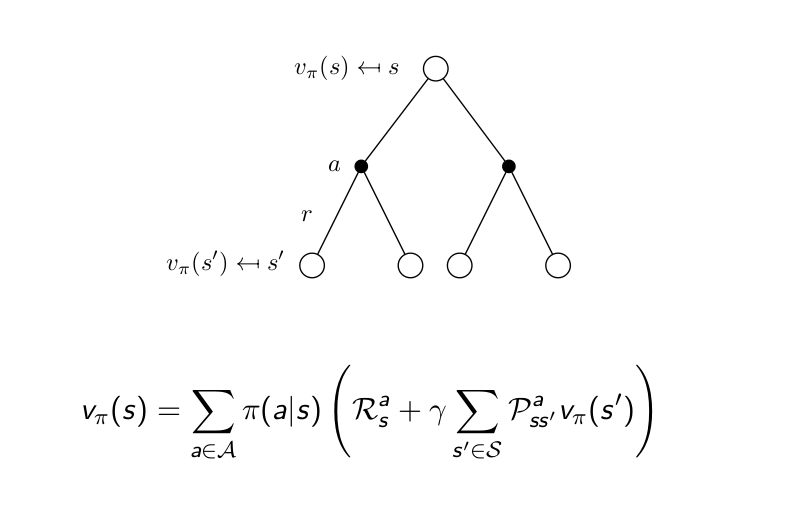 Backup이라는 개념은 이렇습니다. 위에서 언급했듯이 코딩에서의 등호의 의미에 가까우며 오른쪽의 식을 왼쪽에 대입한다는 개념입니다. 즉 위 diagram에서 보면 미래의 값들(next state-value function)으로 현재의 value function을 구한다는 것이 Back-up입니다. 이 Backup은 one step backup이 있고 multi step backup이 있습니다. 또한 Full-width backup(가능한 모든 다음 state의 value function을 사용하여 backup하는 것)과 sample backup(실재의 경험을 통해서 backup)이 있습니다. 뒤에서 다시 언급하겠지만 Full-width backup은 dynamic programming이고 sample backup은 reinforcement learning입니다.
Backup이라는 개념은 이렇습니다. 위에서 언급했듯이 코딩에서의 등호의 의미에 가까우며 오른쪽의 식을 왼쪽에 대입한다는 개념입니다. 즉 위 diagram에서 보면 미래의 값들(next state-value function)으로 현재의 value function을 구한다는 것이 Back-up입니다. 이 Backup은 one step backup이 있고 multi step backup이 있습니다. 또한 Full-width backup(가능한 모든 다음 state의 value function을 사용하여 backup하는 것)과 sample backup(실재의 경험을 통해서 backup)이 있습니다. 뒤에서 다시 언급하겠지만 Full-width backup은 dynamic programming이고 sample backup은 reinforcement learning입니다.
Optimal value function
Bellman optimality equation을 보기 전에 optimal value function에 대해서 살펴보도록 하겠습니다. 강화학습의 목적이 accumulative future reward를 최대로 하는 policy를 찾는 것이라 했었습니다. optimal state-value function이란 현재 state에서 policy에 따라서 앞으로 받을 reward들이 달라지는데 그 중에서 앞으로 가장 많은 reward를 받을 policy를 따랐을 때의 value function입니다. optimal action-value function도 마찬가지로 현재 (s,a)에서 얻을 수 있는 최대의 value function입니다.

즉, 현재 environment에서 취할 수 있는 가장 높은 값의 reward 총합입니다. 위의 두 식 중에서 두 번째 식, 즉 optimal action-value function의 값을 안다면 단순히 q값이 높은 action을 선택해주면 되므로 이 최적화 문제는 풀렸다라고 볼 수 있습니다. 강화학습 뿐만 아니라 Dynamic programming에서도 목표가 되는 optimal policy는 다음과 같습니다. optimal policy는 (s,a)에서 action-value function이 가장 높은 action만을 고르기 때문에 deterministic합니다.

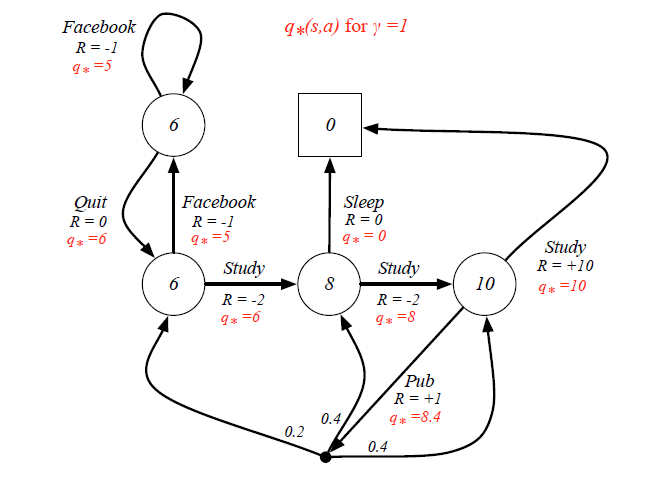
Silver가 수업시간에 예를 들었던 graph를 다시 살펴보면 가운데 8이라고 써져있는 state의 입장에서 optimal action-value function 중에서 가장 큰 8을 선택하면 그것이 optimal policy가 됩니다. 따라서 이 수업을 듣는 아래의 예제에서의 optimal policy는 study --> study --> study가 되는 것 입니다.
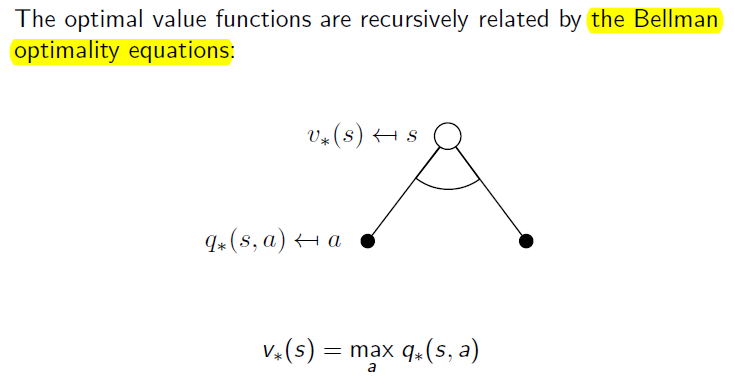
Bellman Optimality Equation
Bellman optimality equation는 위의 optimal value function 사이의 관계를 나타내주는 식입니다. 이전 backup diagram과 다른 점은 아래에는 호의 모양으로 표시된 "max"입니다.
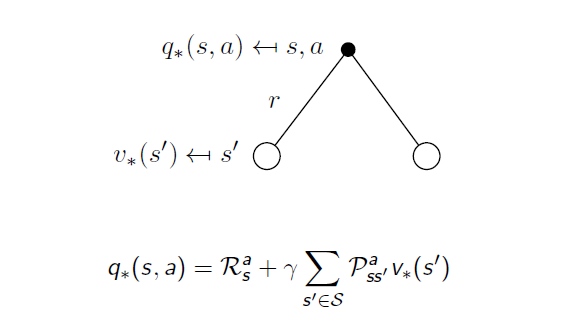
이 두 개의 diagram을 합치면 아래와 같이 됩니다.

이러한 Bellman equation을 통해서 iterative하게 MDP의 문제를 푸는 것을 Dynamic Programming이라 하며 다음 Chapter에서 다루도록 하겠습니다.