Finite Difference Policy Gradient
1. Finite Difference Policy Gradient
이 방법은 수치적인 방법으로서 가장 간단하게 objective function의 gradient를 구할 수 있는 방법입니다. 만약 Parameter vector가 5개의 dimention로 이루어져 있다고 한다면 각 parameter를 $$\epsilon$$만큼 변화시켜보고 5개의 parameter에 대한 Gradient를 각각 구하는 것입니다. parameter space가 작을 때는 간단하지만 늘어날수록 비효율적이고 노이지한 방법입니다. policy가 미분 가능하지 않더라도 작동한다는 장점이 있어서 초기 policy gradient에서 사용되던 방법입니다.

2. Example : Training AIBO
강화학습으로 로봇을 학습시키는 논문중의 Finite Difference Policy Gradient를 사용해서 Sony의 AIBO를 학습시킨 2004년 논문이 있습니다. Silver교수님 수업에서도 아래 그림과 같이 소개되었었습니다.

http://www.sony-aibo.com/
AIBO는 아래와 같이 네 발 달린 강아지모양의 로봇입니다. 이 로봇에는 기본적인 걸음걸이가 있는데 그것이 느려서 더 빠르게 걸음걸이(gait)를 튜닝하는데 강화학습을 사용한 것입니다. 다리의 궤적 자체를 parameterize했기 때문에 Policy gradient 방법이라고 볼 수 있습니다. 다리의 궤적 자체를 policy로 보는 것입니다. 따라서 가장 빠른 걸음걸이를 얻기 위해 12개의 component로 구성되어 있는 parameter vector를 학습시키는 것이 목표입니다. 여기서 objective function은 속도가 됩니다.(따라서 사실 앞에서 언급했던 objective function에 대한 식들은 여기서는 사용하지 않는다는 것)

Gradient를 구하는 방법은 아래와 같습니다.
(1) Parameter vector $$\pi$$ (directly represent the policy of Aibo)
(2) To estimate gradient numerically generate t randomly generated policies
즉, 12개의 parameter를 기존의 parameter보다 미세한 양을 랜덤하게 변화시킨 t개의 policy를 생성하는 것입니다. 그러면 변화가 된 t개의 policy의 objective function(속도)측정합니다.. 12개 parameter 각각에 대해 average score를 계산해서 udate를 하면 됩니다.

아래와 같이 $$\theta_1$$에 대한 gradient를 알고 싶으면 t개의 parameter vector중에서 첫번째 항이 $$\theta_1 - \epsilon_1$$, $$\theta_1 + 0$$, $$\theta_1 + \epsilon_1$$인 것들로 분류한 다음 각 집합의 평균 속도를 구해서 그 중에서 속도가 큰 쪽으로 parameter를 update합니다. 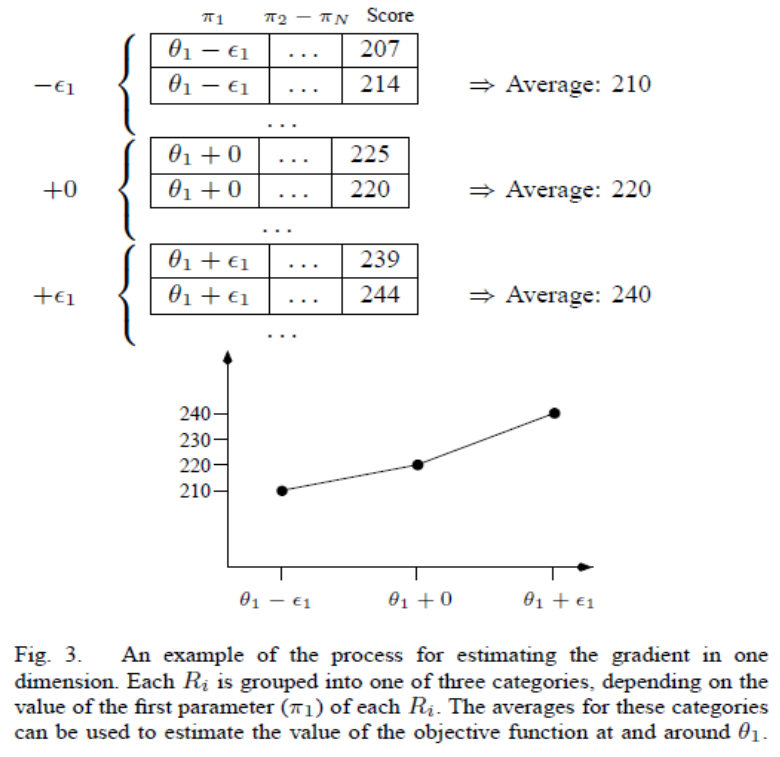
로봇의 걸음걸이 자체를 함수화할 수 없어서 미분 불가능한 문제를 numerical하게 하나하나 해보면서 풀었던 예시였습니다. 최근에 와서는 잘 사용하지 않는 방법입니다.