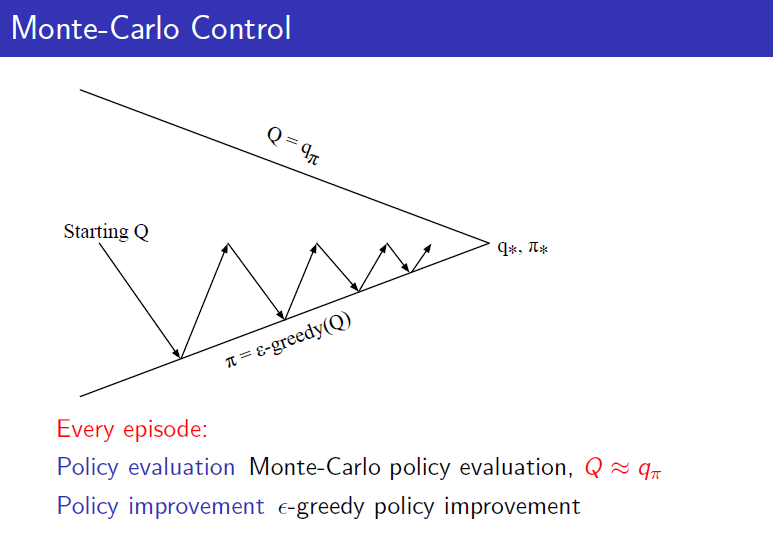
Monte-Carlo Control
1. Monte-Carlo Policy Iteration
이전에는 Monte-Carlo Policy Evaluation = Prediction을 보았습니다. Dynamic Programming때도 evaluation + Improvement = Policy Iteration이 되었듯이 MC에서도 Monte-Carlo Policy Evaluation + Policy Improvement를 하면 Monte-Carlo Policy Iteration이 됩니다.
다시 DP의 Policy Iteration을 생각해봅시다. 현재 policy를 토대로 Value function을 iterative하게 계산해서 policy를 evaluation(true value function에 수렴할 때까지) 그 value function을 토대로 greedy하게 policy를 improve하고 그러한 과정을 optimal policy를 얻을 때까지 반복하였습니다.
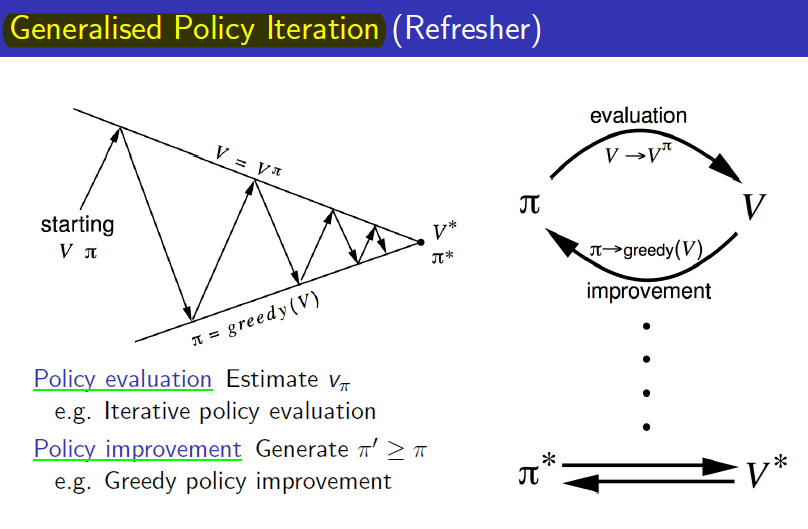
여기에 Policy evaluation만 Monte-Carlo policy evaluation으로 바꾸어주면 Monte-Carlo Policy Iteration이 됩니다.
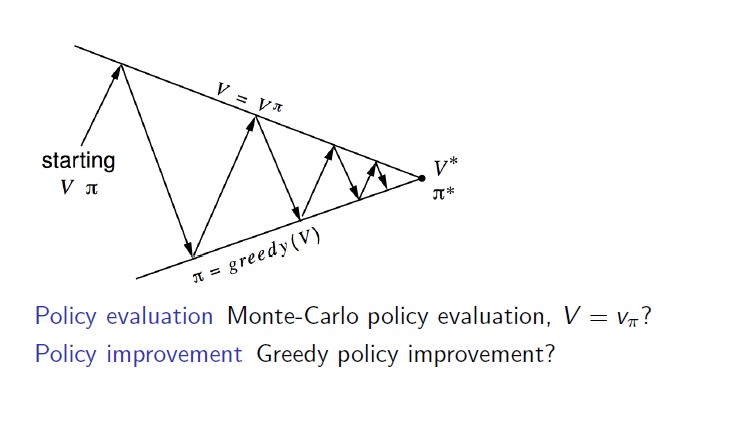
2. Monte-Carlo Control
하지만 Monte-Carlo Policy Iteration에는 세 가지 문제점이 있습니다.
- Value function
- Exploration
- Policy Iteration
(1) Value function
현재 MC로서 Policy를 evaluation하는데 Value function을 사용하고 있습니다. 하지만 value function을 사용하면 policy를 improve(greedy)할 때 문제가 발생합니다. 원래 MC를 했던 이유는 Model-free를 하기 위해서 였는데 value function으로 policy를 improve하려면 MDP의 model을 알아야합니다. 아래와 같이 다음 policy를 계산하려면 reward와 transition probability를 알아야 할 수 있습니다. 따라서 value function 대신에 action value function을 사용합니다. 그러면 이러한 문제없이 model-free가 될 수 있습니다.

(2) Exploration
현재는 policy improve는 greedy policy improvement를 사용하고 있습니다. 하지만 계속 현재 상황에서 최고의 것만 보고 판단을 할 경우에는 optimal로 가는 것이 아니고 local obtimum에 빠져버릴 수가 있습니다. 충분히 exploration을 하지 않았기 때문에 global optimum에 가지 못했던 것입니다. 현재 action a가 가장 높은 value function을 가진다고 측정이 되어서 action을 a만 하면 사실은 b가 더 높은 value function을 가질 수도 있는 가능성을 배제해버리게 됩니다. 마치 대학교나 성적만 보고 사람을 뽑아쓰는 것과 같은 실수일지도 모릅니다. 따라서 그에 따른 대안으로서 일정 확률로 현재 상태에서 가장 높은 가치를 가지지 않은 다른 action을 하도록 합니다. 그 일정 확률을 epsilon이라하며 그러한 improve방법을 epsilon greedy policy improvement라고 합니다. 아래와 같이 선택할 수 있는 action이 m개 있을 경우에 greedy action(가장 action value function이 높은 action)과 다른 action들을 아래와 같은 확률로 나눠서 선택합니다. 이로서 부족했던 exploration을 할 수 있게 된 것 입니다.

(3) Policy Iteration
Policy Iteration에서는 evaluation과정이 true value function으로 수렴할 때까지 해야하는데 그렇게 하지 않고 한 번 evaluation한 다음에 policy improve를 해도 optimal로 간다고 말했었습니다. 그것이 Value iteration이었는데 Monte-Carlo에서도 마찬가지로 이 evaluation과정을 줄임으로서 Monte-Carlo policy iteration에서 Monte-Carlo Control이 됩니다. 결국 Monte-Carlo Control은 다음과 같습니다.
3. GLIE
GLIE란 Greedy in the Limit with Infinite Exploration을 뜻하고 sutton교수님 책에는 안 나왔지만 Silver교수님 강의에서 나왔던 내용입니다. 학습을 해나감에 따라 충분한 탐험을 했다면 greedy policy에 수렴하는 것을 말합니다. 하지만 epsilon greedy policy로서는 greedy하게 하나의 action만 선택하지 않는데 이럴 경우는 GLIE하지 않습니다. 보통 learning을 통해서 배우려는 optimal policy는 greedy policy입니다. 따라서 exploration문제 때문에 사용하는 epsilon greedy에서 epsilon이 시간에 따라서 0으로 수렴한다면 epsilon greedy 또한 GLIE가 될 수 있습니다. 후에는 이러한 문제를 off-policy control로서 Q-learning을 쓰면서 해결하게 됩니다.

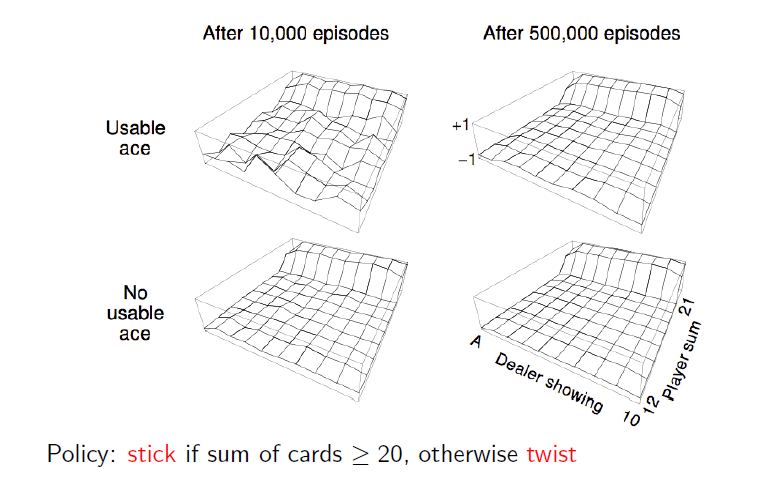
4. Blackjack
Monte-Carlo prediction에서 봤던 블랙잭 예제를 policy evaluation + policy improvement를 해서 다시 계산해보면, 즉 agent를 학습시켜보면 아래와 같이 됩니다. 그 아래의 Monte-Carlo Policy evaluation과 비교를 하면 전체적인 value function이 발전되었다는 것을 알 수 있고 이 policy가 optimal policy가 됩니다.