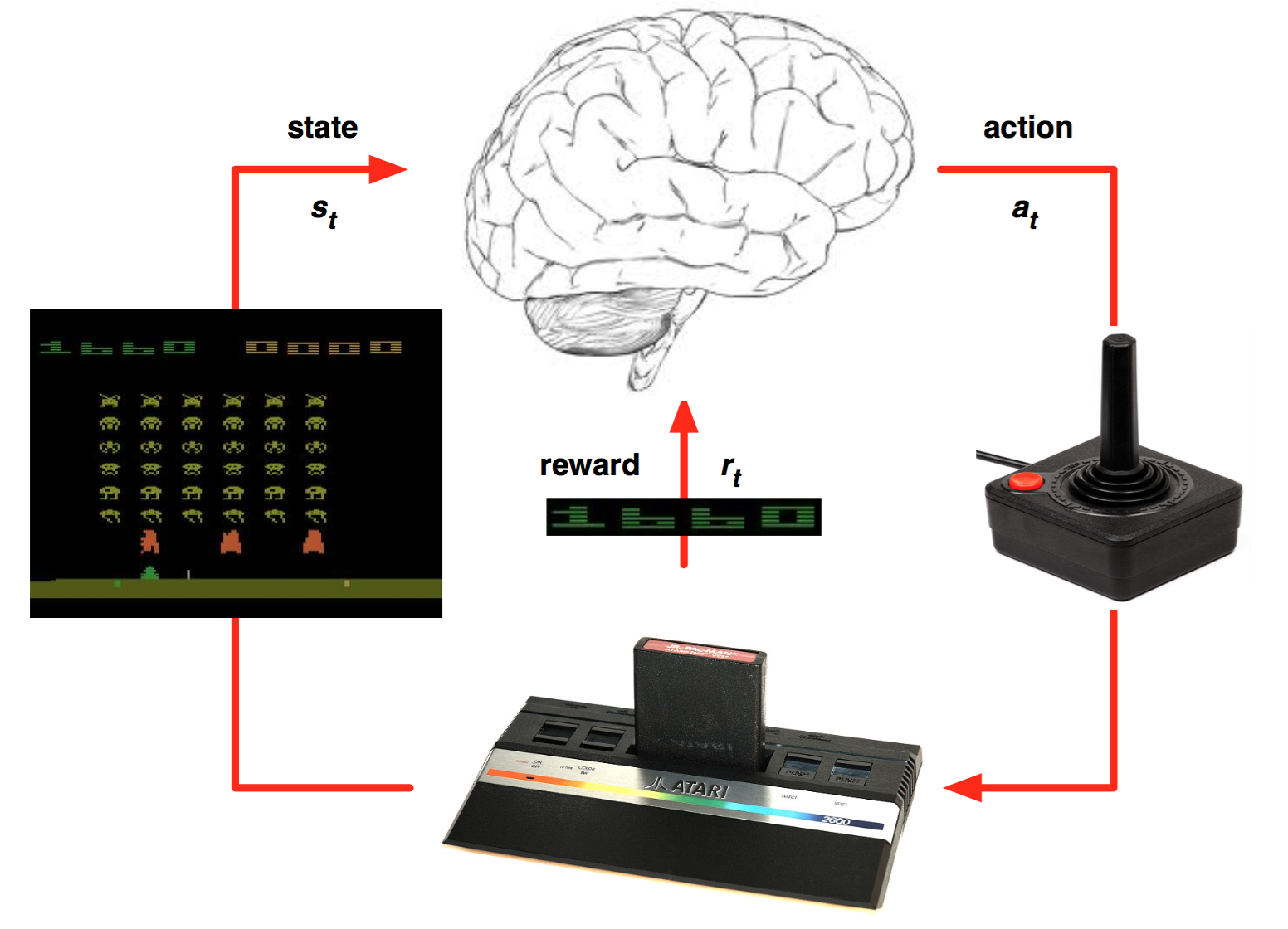
Deep Q Networks
첫 번째 chapter에서 Atari game의 학습에 대해서 소개했었습니다. 이 예제는 Playing atari with deep reinforcement learning 이라는 논문에서 나온 것으로 링크는 아래와 같습니다. 강화학습 + 딥러닝으로 atari라는 고전 게임을 학습시킴으로 deep reinforcement learning의 시대를 열어주었습니다. https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
이 논문의 abstract는 다음과 같습니다.
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards. We apply our method to seven Atari 2600 games from the Arcade Learning Environment, with no adjustment of the architecture or learning algorithm. We find that it outperforms all previous approaches on six of the games and surpasses a human expert on three of them.
이 논문의 주목할 점은 다음과 같습니다.
- input data로 law pixel를 받아온 점
- 같은 agent로 여러 개의 게임에 적용되어서 학습이 된다는 점
- Convolutional neural network를 function approximator로 사용
- Experience Replay
Deep Q Network라는 개념이 여기서 처음 소개되었는데 아래와 같이 action value function을 approximate하는 model로 deep learning의 model을 도입했는데 그 중에서 convolutional network를 도입해서 network를 훈련시키는 것이 DQN이라고 소개하고 있습니다.
We refer to convolutional networks trained with our approach as Deep Q-Networks (DQN).
Convolutional neural network(CNN)은 최근의 딥러닝 열풍을 몰고온 장본인으로서 이미지를 학습시키는 데 최적화된 Neural Network모델입니다. 이 모델을 사용하면 화면 게임 픽셀 데이터 그 자체로 학습을 시킬 수 있습니다. 그렇기 때문에 따로 게임마다 agent설정을 달리해주지 않아도 여러 게임에 대해 한 agent로 학습시킬 수 있는 것 입니다.
Neural Network에 들어가는 input data에 대해서는 다음과 같이 언급하고 있습니다.
Working directly with raw Atari frames, which are 210X160 pixel images with a 128 color palette, can be computationally demanding, so we apply a basic preprocessing step aimed at reducing the input dimensionality. The raw frames are preprocessed by first converting their RGB representation to gray-scale and down-sampling it to a 110X84 image. The final input representation is obtained by cropping an 84X84 region of the image that roughly captures the playing area
이 단계를 "Preprocessing"이라고 합니다. CNN이 학습할 수 있는 형태로 게임의 화면을 변화시켜주는 것으로서 일단 색을 없애고 이미지의 크기를 줄이고 위아래의 불필요한 정보를 없애주며 정사각형의 이미지로 만들어주는 과정입니다. 이러한 이미지를 4개씩 묶어서 CNN으로 집어넣게 됩니다.
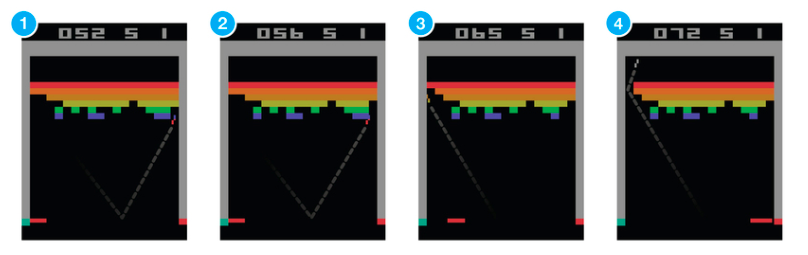 https://www.nervanasys.com/demystifying-deep-reinforcement-learning/
https://www.nervanasys.com/demystifying-deep-reinforcement-learning/
state가 갑자기 pixel data되어서 헷갈릴 수도 있다. 하지만 agent의 입장에서는 단지 data의 형태가 바뀌었을 뿐이고 화면을 하나의 상태로 인식해서 그 상태에서 어떤 행동을 했을 때의 reward를 기억하고 있는 것 입니다.
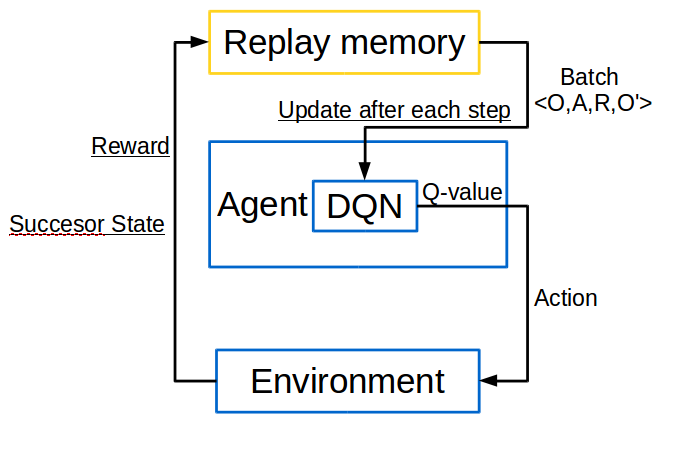
이 알고리즘을 그림으로 나타내보자면 아래와 같습니다. chapter 8에서 언급했던 experience replay를 사용하고 있습니다. transition data들을 replay memory에 넣어 놓고 매 time step마다 mini-batch를 랜덤으로 memory에서 꺼내서 update를 합니다. learing 알고리즘으로는 q-learning을 사용하고 있습니다.
알고리즘은 아래와 같습니다.
 replay memory는 N개의 episode를 기억하고 있을 수 있는데 N개가 넘어가면 오래된 episode부터 뺍니다.
replay memory는 N개의 episode를 기억하고 있을 수 있는데 N개가 넘어가면 오래된 episode부터 뺍니다.
episode마다 어떻게 update할까요? loss function을 정의하고 그 gradient를 따라서 업데이트합니다. mini-batch data에 대해서 bootstrap으로 q-learning이 했던 것처럼 $$r+\gamma maxQ(s',a')$$을 현재 Q가 update가 되어야할 target으로 잡고 그 error를 quadratic하게 잡고서 gradient를 취하면 아래와 같습니다.

chapter8에서 배웠던 내용 활용한 것으로서 달라지는 것은 $$\nabla _\theta Q(s,a,\theta)$$를 어떻게 구하냐입니다. 사실은 이 부분은 딥러닝에 대해서 깊게 들어가야하는 부분인데 tensorflow같은 라이브러리들이 잘 되어있어서 함수를 호출하면 알아서 계산해줍니다.