Policy Gradient
1. Policy Gradient
현재 강화학습에서 가장 "hot"하다고 볼 수 있는 방법이 Policy Gradient입니다. 강화학습의 기본 교재인 Sutton 교수님의 책에는 Policy Gradient가 몇 장 안나와 있어서 Silver교수님 RLcourse 7번째 Policy Gradient강의를 통해 그 개념을 접하고 이해하시는 것을 추천드립니다. (2nd edition에서는 이 부분이 추가되었습니다.)
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
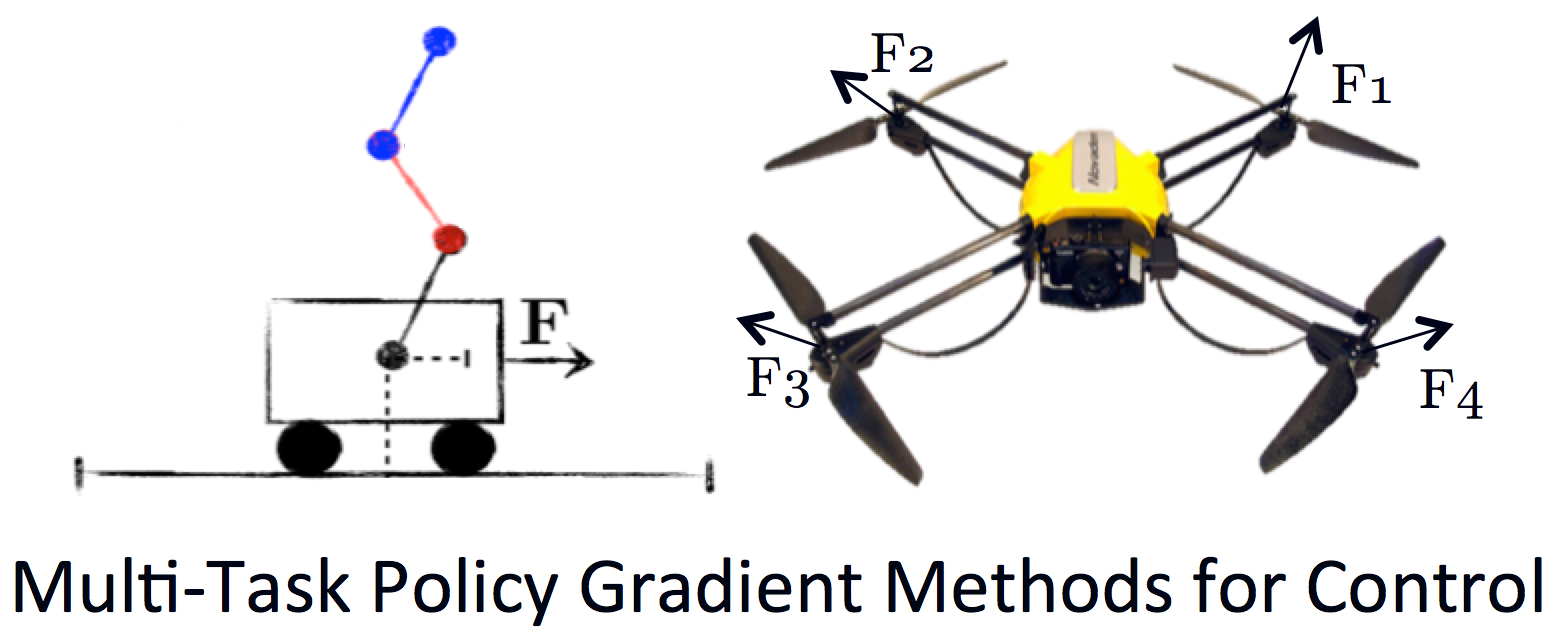
 AlphaGo의 알고리즘도 "Policy Gradient with Monte-Carlo Tree Search"라고 합니다. 또한 실재 로봇이나 헬리콥터, 드론같은 적용에 적합한 방법이라고 합니다. 처음에 제가 강화학습에 관심을 가지게 된 계기도 드론의 자율주행이었기 때문에 Policy Gradient는 상당히 흥미롭게 다가왔습니다.
AlphaGo의 알고리즘도 "Policy Gradient with Monte-Carlo Tree Search"라고 합니다. 또한 실재 로봇이나 헬리콥터, 드론같은 적용에 적합한 방법이라고 합니다. 처음에 제가 강화학습에 관심을 가지게 된 계기도 드론의 자율주행이었기 때문에 Policy Gradient는 상당히 흥미롭게 다가왔습니다.
2. Value-based RL VS Policy-based RL
지금까지 저희가 다루었던 방법들은 모두 "Value-based" 강화학습입니다. 즉, Q라는 action-value function에 초점을 맞추어서 Q function을 구하고 그것을 토대로 policy를 구하는 방식입니다. 이전에 했던 DQN 또한 Value-based RL으로서 DNN을 이용해 Q-function을 approximate하고 policy는 그것을 통해 만들어졌습니다.

그와 달리 Policy-based RL은 Policy자체를 approximate해서 function approximator에서 나오는 것이 value function이 아니고 policy자체가 나옵니다. Policy자체를 parameterize하는 것입니다. 어떻게 보면 evolutionary 알고리즘의 개념에 더 가깝다고 할 수도 있습니다. 하지만 지금까지 저희가 살펴봤듯이 evolutionary 알고리즘과 달리 강화학습은 환경과의 상호작용이 있습니다.

왜 이렇게 할까요?? Policy Gradient의 장점과 단점은 다음과 같습니다.
- 기존의 방법의 비해서 수렴이 더 잘되며 가능한 action이 여러개이거나(high-dimension) action자체가 연속적인 경우에 효과적입니다. 즉, 실재의 로봇 control에 적합합니다.
- 또한 기존의 방법은 반드시 하나의 optimal한 action으로 수렴하는데 policy gradient에서는 stochastic한 policy를 배울 수 있습니다.(예를 들면 가위바위보)
하지만 local optimum에 빠질 수 있으며 policy의 evaluate하는 과정이 비효율적이고 variance가 높습니다.

기존 방법의 문제를 살펴보도록 하겠습니다. Value-based RL 방식에는 두 가지 문제가 있습니다.
- Unstable
 Value-based RL에서는 Value function을 바탕으로 policy계산하므로 Value function이 약간만 달라져도 Policy자체는 왼쪽으로 가다가 오른쪽으로 간다던지하는 크게 변화합니다. 그러한 현상들이 전체적인 알고리즘의 수렴에 불안정성을 더해줍니다. 하지만 Policy자체가 함수화 되어버리면 학습을 하면서 조금씩 변하는 value function으로 인해서 policy또한 조금씩 변하게 되어서 안정적이고 부드럽게 수렴하게 됩니다.
Value-based RL에서는 Value function을 바탕으로 policy계산하므로 Value function이 약간만 달라져도 Policy자체는 왼쪽으로 가다가 오른쪽으로 간다던지하는 크게 변화합니다. 그러한 현상들이 전체적인 알고리즘의 수렴에 불안정성을 더해줍니다. 하지만 Policy자체가 함수화 되어버리면 학습을 하면서 조금씩 변하는 value function으로 인해서 policy또한 조금씩 변하게 되어서 안정적이고 부드럽게 수렴하게 됩니다.
- Stochastic Policy
때로는 Stochastic Policy가 Optimal Policy일 수 있습니다. 가위바위보 게임은 동등하게 가위와 바위와 보를 1/3씩 내는 것이 Optimal한 Policy입니다. value-based RL에서는 Q function을 토대로 하나의 action만 선택하는 optimal policy를 학습하기 때문에 이러한 문제에는 적용시킬수가 없습니다.
3. Policy Objective Function
이제 기존의 방법처럼 action value function을 approximate하지 않고 policy를 바로 approximate할 것 입니다. 학습은 policy를 approximate한 parameter들을 update해나가는 것 입니다. 이 parameter을 update하려면 기준이 필요한 데 DQN에서는 TD error를 사용했었습니다. 하지만 Policy Gradient에서는 Objective Function이라는 것을 정의합니다. 정의하는 방법에는 세 가지가 있습니다. state value, average value, average reward per time-step입니다. 똑같은 state에서 시작하는 게임에서는 처음 시작 state의 value function이 강화학습이 최대로 하고자 하는 목표가 됩니다. 두 번째는 잘 사용하지 않고 세 번째는 각 time step마다 받는 reward들의 expectation값을 사용합니다. 사실은 time-step마다 받은 reward들을 discount시키지 않고 stationary distribution을 사용해서 어떤 행동이 좋았나에 대한 credit assignment문제를 풀고있지 않나 생각됩니다.

Stationary distribution은 처음 접하는 개념일겁니다. sutton교수님의 policy gradient논문에서는 stationary distribution을 다음과 같이 정의하고 있습니다.
https://webdocs.cs.ualberta.ca/~sutton/papers/SMSM-NIPS99.pdf

개인적으로는 위에서 언급했다시피 각 state에 머무르는 비율로 이해하고 있습니다. 이러한 stationary distribution이 어떻게 구현되었나 궁금하기도 합니다.
Policy Gradient에서 목표는 이 Objective Function을 최대화시키는 Policy의 Parameter Vector을 찾아내는 것입니다. 그렇다면 어떻게 찾아낼까요? 바로 Gradient Descent입니다. 그래서 Policy Gradient라고 불리는 것입니다. 다음에서는 Objective Function의 Gradient를 어떻게 구하는 지에 대해서 보겠습니다.
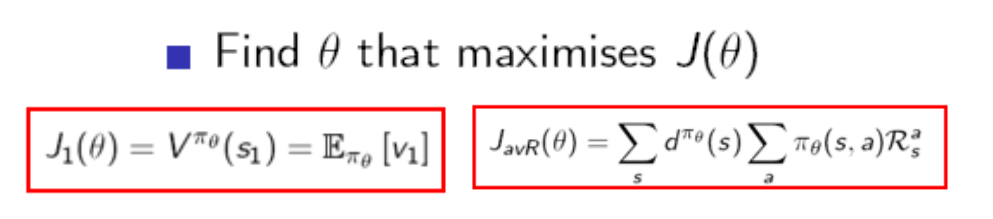
4. How to get gradient of objective function
Objective Function의 Gradient를 구하는 방법이 핵심인데 세 가지 방법이 있습니다.
- Finite Difference Policy Gradient
- Monte-Carlo Policy Gradient
- Actor-Critic Policy Gradient
하나씩 차근 차근 살펴보도록 하겠습니다.